Fantastic Scandals and How to Research Them
Through this series of activities, the students learn how to critically assess the potential and impact of digital methods on the field of media and communication in relation to both qualitative and quantitative methods. The activities center around the use of Voyant and allows students to practice using the programme for empirical studies through hands-on exercises.
Motivation
Motivation
Our students have to learn how to work with social media and online data. This is not only relevant for what we study in media studies but is also what they might work with and be competent to understand and analyse in their future jobs. It was my motivation to prepare them accordingly.
Use of technology
Use of technology
-
GoFullPage (Google Chrome extension)
-
Voyant tools (https://voyant-tools.org/)
-
Twitter developer accounts for API access for each student
-
Jupyter notebooks in Google Collab
-
Instant data scraper
-
Microsoft Office Excel to save, edit, and manage data
Students were supposed to learn about different paths of data collection (API and web-scraping). Therefore, they had to use the listed different digital tools needed to perform these tasks. Voyant is a digital tool that allows for data mining (distant reading) of large text corpora, yet without having any programming knowledge. The selected tools and approaches fit our students’ abilities better than high-level computational methods and tools.
Outcome
Outcome
Overall, the students learned to navigate through the research process with large social media data sets to answer their research questions. This means they gained knowledge about digital data collection and analysis that will allow them to critically assess the potential of digital methods and equipped them with the skills to apply (some) them in their own research. At the same time, they learned what they are not capable to do themselves (programming, computational analysis) and that there are solutions, such as Voyant, that will still allow them to analyse large corpora of data available on social media. The course demanded a high degree of independent work and responsibility for the group projects. It also gave the students the opportunity to develop competencies as project managers and researchers, and allowed them to develop their academic identity. In sum, the knowledge, skills, and competencies they acquired hopefully prepared them for their MA thesis and their future jobs.
Activities
The course of the pilot project consisted of 7 lessons of 2 hours duration. The pilot project ran as a part of the MA course “Research Design and Empirical Methods”, from late September until early November 2022.
-
In the first part, we did what I coined a "deep dive session" into the methodological challenges of researching digital communication.
-
The goal was for the students to understand what digital methods are, why we use them, and what challenges digital methods pose.
-
In a group exercise, the students discussed the literature and comprised the different challenges the authors identify. We then discussed if/how the 8 years that lie between the two publications led to a change in challenges and arguments regarding digital methods and their impact.
-
-
The second and third parts concerned the problematic conditions of online research, data privacy, and ethics in digital methods research.
-
The goal was for the students to understand and critically assess the challenges with data access to social media communication. The aim was to create awareness for ethical aspects, such as privacy and data security, and for the students to learn practices and rules for ethical research.
-
The second session consisted of an open discussion of the challenges researchers (and the students) face when accessing social media. In an exercise, students researched and skimmed the terms of service of social media platforms to find out what they allow/forbid researchers regarding data access, analysis, and distribution.
-
The third sessions consisted of a lecture on the topic with subsequent open discussion in the plenum. Students then collected ethical issues and problems particularly related to their empirical study, which we discussed afterward: https://ucph.padlet.org/manuelmenke/rgug908orazzg96j
-
-
The fourth and fifth sessions were about learning practical skills to retrieve data. This meant to acquire an understanding of how the data scientists at KU wrote a script and collected the data as well as learning to use a web-scraping tool.
-
Students used the Google Jupyter notebook with a prewritten script to collect some basic Twitter data. The code was explained in class and students ran it in different exercises.
-
In the fifth session, students used the web-scraping tool “Instant data scraper” (Chrome extension) to collect data from Reddit.
-
-
In the sixth and seventh session, the goal was for the students to understand the possibilities and limits of text mining aka, distant readings of data. Learning how to prepare data and use it with Voyant tools for exploring and visualizing large textual corpora.
-
The teacher introduced different tools within Voyant and the Voyant Wiki.
-
Students were then handed a large data set with Reddit comments.
-
They then prepared the data set in Excel, uploaded it to Voyant, and analyzed the data using the available tools.
-
In the last session, we focused on visualization and the export of graphs.
-
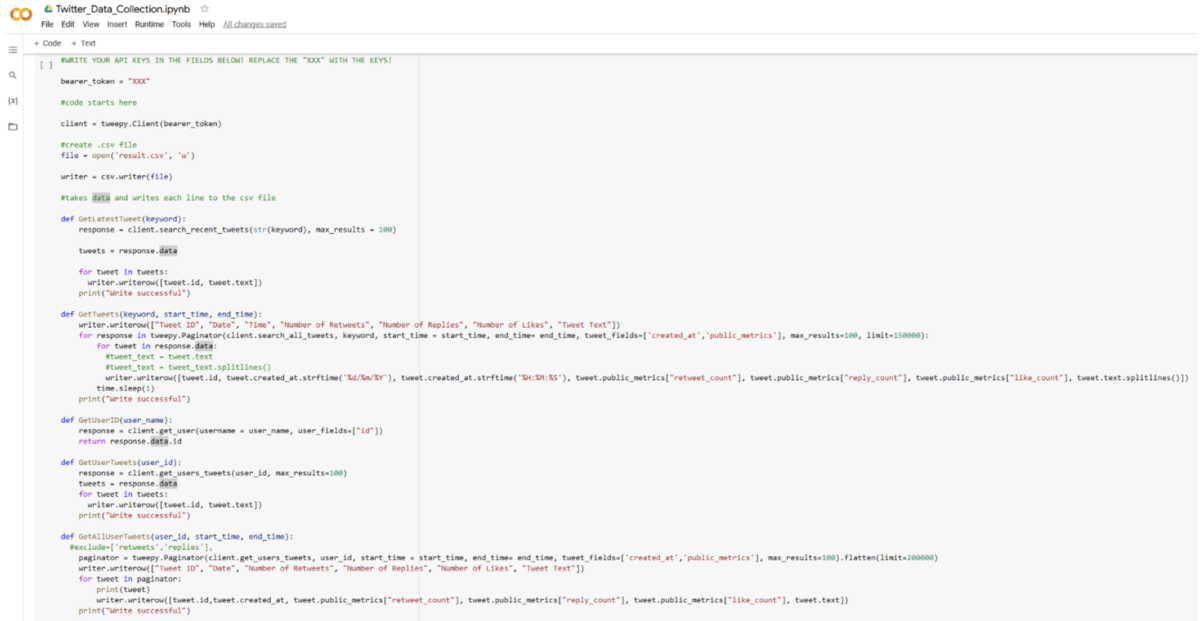
Screenshot of Google Jupyter Notebook with code to access Twitter API and download data
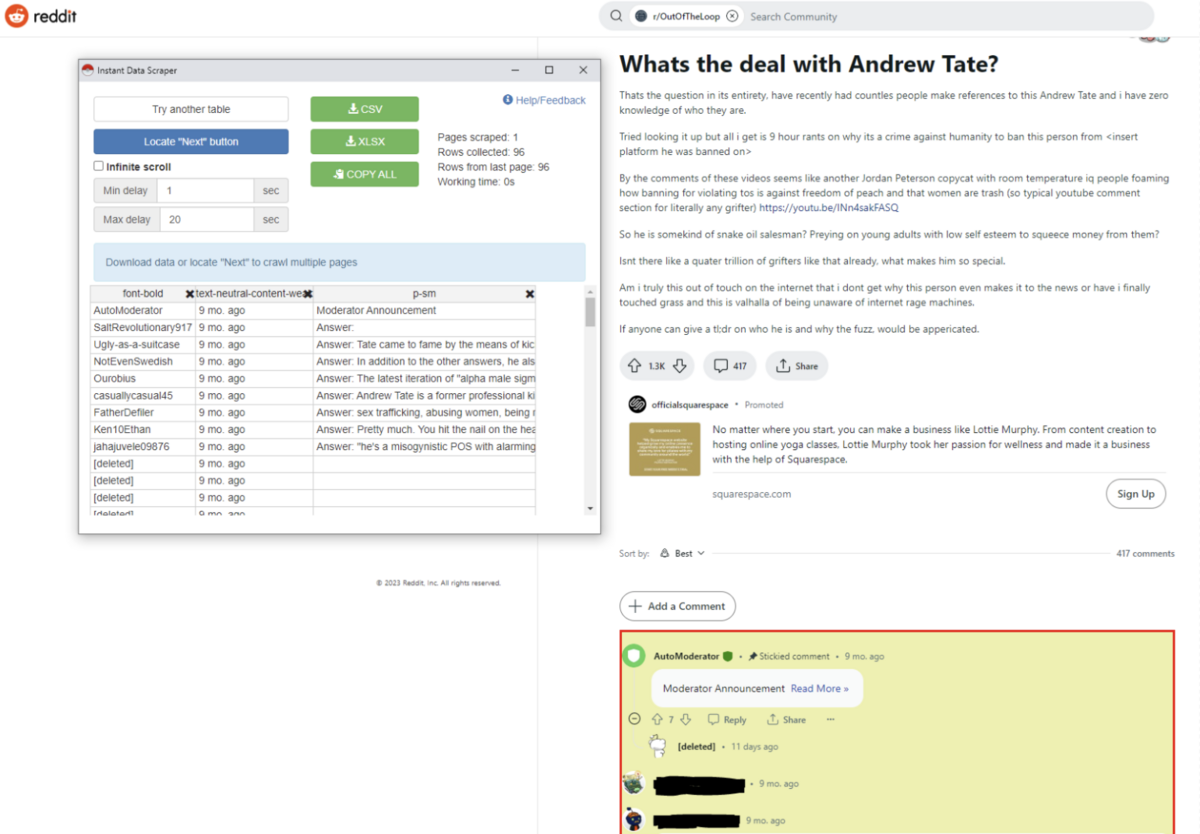
Screenshot of Instant Data Scraper Chrome Add-on used in Reddit.

Example of a basic Voyant Cirrus visualization (word cloud) used by students to present the most common words in a Twitter data set on the women's protest in Iran.
End of semester poster presentation of students' projects
Ressources and support
Ressources and support
-
Texts concerning:
- Digital methods
- “Digital revolution in the social sciences”
- APIs and social media
- Cambridge Analytica
- Ethical issues
-
Data sets with Twitter and Reddit data
-
Voyant Wiki
-
Padlet for collecting points on ethical issues
-
Walkthrough of Google notebook script
-
Walkthrough of Voyant Tools
Challenges and advice
Challenges and advice
The biggest challenge was that the nine groups wanted to work with different data from different platforms. This created huge challenges regarding the data collection. It costs time and requires individual solutions to collect the data. This resulted in a lot of coordination with the data scientists from KU who invested (too) much time to code for the APIs and collect data. The students also saw little use in working with the Google Jupyter Notebooks because they knew that they would not be able to replicate the coding the data scientists prepared.
A piece of advice for other teachers is to try to work with data from one platform to be able to use a one-size-fits-all solution for data collection. Reddit (so far) is the easiest platform to gain access both over API and with web-scraping tools. Time management is very important to be able to get the data the students want for their projects in time and there is no delay because of complications. Complications are the norm because the rules to access social media platforms are constantly changing and old solutions might become obsolete or illegal.
Manuel Menke on his teaching case:
Basic information:
Teacher: Manuel Menke
Faculty: Humanities, University of Copenhagen
Department: Department of Communication
Course: Research Design and Empirical Methods
Level of study: MA
Teaching method: Small class teaching, practical exercises
Number of students: 26
Duration: Series of activities within full course on digital methods
Academic objective
In order to qualify their work with small and large projects based on qualitative data, as well as data compilation and treatment in relation to subsequent work tasks, students should:
-
Be familiar with NVivo (software for qualitative data analysis)
-
Have a basic understanding of how NVivo can support their analytic work (through the various possibilities for harvesting, importing and treating data, and visualizing analysis and results)